 查看论文
查看论文
 实验代码
实验代码
扩散模型基础学习
2024年4月 - 5月
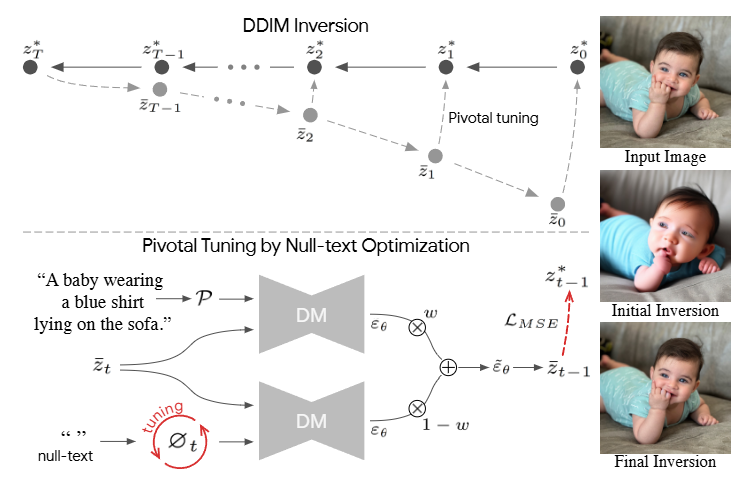
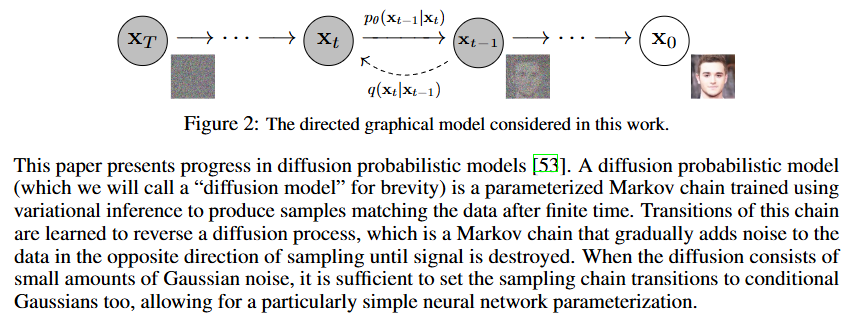
系统学习 DDPM 马尔可夫链原理及 DDIM 确定性加速采样,初步接触 AudioEditor 框架,研究空文本反演(Null-text Inversion)实现音频编辑的方法。
查看详情从理论学习到算法实现的完整技术路线
深入研究扩散模型的前向加噪与反向去噪过程,重点对比 DDIM 的确定性采样与 DPM-Solver 的 ODE 路径反推机制,为音频反演提供坚实的数学基础。系统掌握了马尔可夫链原理及确定性加速采样技术。
完成 RTX 4090 工作站深度学习环境配置,包括双系统分区优化、CUDA 驱动安装及网络代理解决。设计了 128G 内存下的 Swap 文件方案及 SSD 训练加速分区,确保大规模模型推理的稳定性。
针对 Stable Audio 的特殊架构,成功开发并验证了一阶与二阶 DPM-Solver 反演流程。通过重新实现可微的 ODE 求解函数,解决了 Scheduler 中梯度断裂(detach)问题,显著提升了真实音频在潜空间中的重建精度。
2024年4月 - 5月
系统学习 DDPM 马尔可夫链原理及 DDIM 确定性加速采样,初步接触 AudioEditor 框架,研究空文本反演(Null-text Inversion)实现音频编辑的方法。
查看详情
2024年5月 - 6月
规划将图像领域 Rectified Flow Inversion 迁移至音频的任务书,在 RTX 3060 环境下跑通初步音频编辑代码,识别时序依赖建模等技术挑战。
查看详情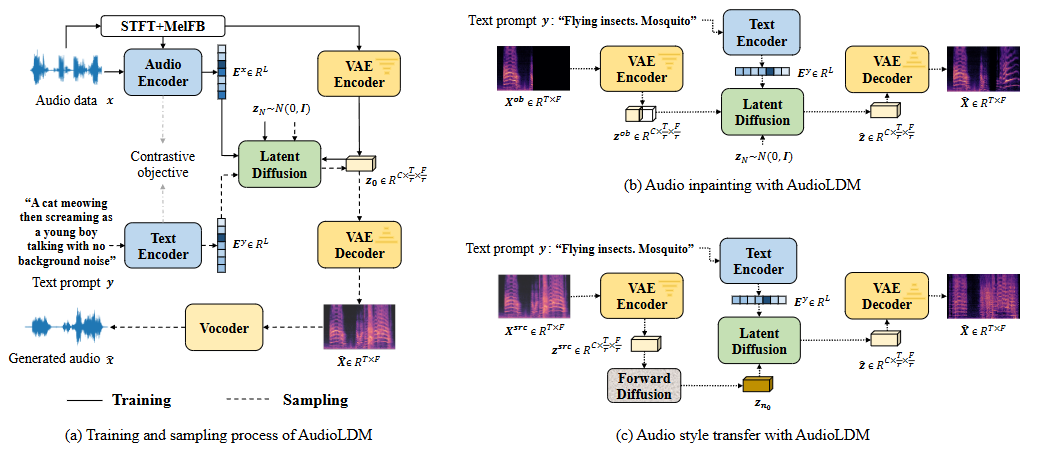
2024年6月
配置 Dell Precision 3660 工作站,设计 Swap 文件方案及 SSD 训练加速分区。解决 Ubuntu 系统下无线网卡驱动离线安装及双系统引导等底层难题。
查看详情
2024年7月
深挖 Stable Audio 源代码,识别出 Cosine DPMSolver 调度器。提出基于优化的反演策略,通过迭代优化初始噪声 z_T 使重建损失最小化。
查看详情
2024年8月
发现并分析 Scheduler step() 方法中的梯度断裂问题,通过重新实现可微 ODE 求解函数,成功复现一阶与二阶 DPM-Solver 反演。实验显示二阶反演在音频重建效果上非常理想。
查看详情
2024年8月
对比 DDIM、ReNoise 及 Null-text Inversion 在 Stable Audio 上的表现,验证在特定 Prompt 引导下,正向 Scale=7 与反向 Scale=1 的配置能获得最佳的生成与反演平衡。
查看详情音频反演前后对比试听 · 点击播放按钮切换不同算法,进度位置自动同步便于 A/B 对比
A woman is giving a speech amid applause
a_relaxing_piano_melody_in_a_calm_environment
反演是将真实音频通过扩散模型的前向过程映射到潜空间噪声表示的技术。通过精确重建原始噪声,可以在不改变音频主体内容的前提下,对音频的属性(如音色、节奏、风格)进行可控编辑。
DDIM 使用确定性采样路径进行反演,适合简单场景但精度有限。DPM-Solver 基于 ODE 理论,利用高阶数值方法(一阶/二阶)更精确地反推扩散路径,在音频重建中表现出更高的保真度和稳定性。
发现 Diffusers 库中 Scheduler 的 step() 方法在计算过程中调用了 detach() 导致梯度链断裂。解决方案是绕过标准 Scheduler,重新实现可微分的 ODE 求解函数,确保反向传播能够正常进行,从而实现对初始噪声的优化。
主要使用 Dell Precision 3660 工作站,配备 RTX 4090 显卡和 128GB 内存。同时测试了联通云 GPU 服务器的 4×A100 环境配置,扩展了算力资源。双系统(Windows + Ubuntu)设计兼顾日常办公与深度学习训练需求。
非生成源音频(真实外部音频)在 VAE 编码过程中仍存在量化误差;部分 Prompt 下的反演一致性需要通过调节 init_noise_sigma 等超参数进一步优化;跨时长音频的时序一致性保持也是后续研究方向。